
Utilization of imitation and anticipation mechanisms to bootstrap an evolutive distributed artificial intelligence system
| Christophe Meyer Laforia - IBP - CNRS Université Pierre et Marie Curie 4, Place Jussieu 75252 Paris France ch.meyer@free.fr |
| Jean-Gabriel Ganascia Laforia - IBP - CNRS Université Pierre et Marie Curie 4, Place Jussieu 75252 Paris France ganascia@laforia.ibp.fr |
Introduction
An evolutive distributed artificial intelligence system often entails difficult bootstrapping problems because, when it is randomly initialized, it has no expertise on the domain, or when it is initialized by an human expert, there is the problem of translating his knowledge into a convenient format, which can be long, tedious and difficult.
As a potential solution to such problems, we suggest to embed the human expert in the system and to allow other agents to imitate and to anticipate his behavior. Beyond bootstrapping, imitation and anticipation can also be used to diffuse knowledge among agents and therefore to accelerate the system’s evolution.
Our methodology will be illustrated herein within the context of the ALESIA application.
Imitation and Anticipation
Mechanisms of knowledge transmission within some animal communities provided insights for the elaboration of our method. It turns out that when he is just born, an animal doesn’t know anything about its environment, and relies only on its instinct to survive. Its education can be assimilated to a bootstrapping process that is usually performed in two different ways : by being taught or by personal experience. Animals do not possess cognitive tools (notably speech) that would allow them to teach as humans do. They can only demonstrate what to do in what situations. Young animals learn by observing and imitating their parents or relatives. It is, for example, well known that geese, ducks and swans migrate in flocks composed of mixed juveniles and adults and that the juveniles learn the route characteristic of their population, stopping at traditional rest places, and breeding and overwintering localities (Schimdt-Koenig, 1979). It is also well known that, because for many years milk has been delivered to houses in England and left on the doorstep early in the morning, blue tits learned to peck through the foil bottle tops and to help themselves to the reach cream floating on top. Hinde and Fisher (1951) reported that this practice first appeared in particular localities and gradually spread, suggesting that birds were learning from each other. Another well known case of imitation concerns the population of Japanese macaques of Koshima islands (Kawanura , 1963). To bring the monkeys into the open where they could be observed more readily, scientists supplemented their diet by scattering sweet potatoes on the beach. A 16-month-old female was observed to wash the sand off her potatoes in a stream. She continued her practice on a regular basis and soon was imitated by other monkeys, particularly those of her own age. Within 10 years, the habit has been acquired by the majority of the population, with the exception of adults more than 12 years old and infants of less than a year.
In a variety of circumstances, the acquaintance an animal gets with the behavior of another animal leads, not to the imitation of this behavior, but to its anticipation. This is for example the case when a predator anticipates the movement of its prey. During cooperative hunting of wild dogs, lions or hyenas, it is often observed that an individual in the rear sometimes will cut corners in an attempt to head off prey. Likewise, wolves chasing an intended victim may split up, some continuing to chase at the heels, while others run ahead, apparently in an effort to head it off (Murie, 1944).
Some conclusions concerning the role of imitation in animal behavior are contested (Galef, 1992 ; Heyes, 1994). For example, Heyes says that most of the time, there is not any imitation in animal behavior but a particular kind of reinforcement learning. Despite these critical remarks, the observations concerning this particular type of animal communities have led us to conceive a new type of knowledge transmission in distributed artificial intelligence systems.
According to such considerations, our bootstrapping mechanisms relies on the following principle : after having endowed agents with simple initial knowledge and tools that make it possible to imitate and anticipate the behavior of other agents, the designer takes the place of one agent within the system. This particular agent interacts with the other agents from whom it is indistinguishable. The designer acts in the system with his own expertise and is, a priori, very effective during the initialization (or initiation) phase of the system. As other agents attempt to model his behavior and to anticipate his actions, they learn and improve their behavior. This original form of bootstrapping exhibits several advantages : the human expert is free from the classic problem of action or choice justification and also from the problem of translating his expertise in a format imposed by the system’s implementation. He is only committed to be effective, so that his knowledge can spread.
An ordinary agent imitating an efficient or intelligent behavior can be imitated by another agent and thus, contributes to accelerate knowledge diffusion. This is also the case when an intelligent behavior is discovered by other means (for example, by personal experience) by a computer agent that is modelized by others agents.
Our application calls upon a classifier system (Holland et al, 1975) in which agents obey to behavioral rules and to utilization strategies of these rules that are based on their selective values (fitness), i.e., on an on-line assessment of how useful each rule has been in the past. Within such a system, rules evolve thanks to a genetic algorithm (Holland, 1975 ; Goldberg, 1989) and are expressed in a given format chosen so as to fit this algorithm. As a consequence, rules created by imitation are committed to be expressed in the same format than rules that govern the behavior of the imitating agents. For this reason, this process will be called modelling instead of mere imitation from now on. As for anticipation, it amounts to discover how the opponent updates the selective value of its behavioral rules, in order to predict what its next action will be and to select an appropriate counter-action.
To follow on the analogy with animal communities and natural mechanisms, our system deals with successive generations and implements an artificial selection process. According to such a process, individuals that survive and reproduce are those that are efficient and adapted, others are eliminated. Thus, when an human expert has taught all what he knows and when computer agents that have modelled him become more efficient than him, he is eliminated from the system that, henceforth, can evolve alone. However nothing prevents the designer or an expert to "return" later on in the system if necessary ( in case of freezing, decline of performances, discovery of more adapted behaviors, etc. ).
The fact that rules created for modeling have the same structure than behavioral rules makes it possible to genetically "cross" a computer agent with a “ modelled behavioral representation ” of an human expert. We call the result of such a crossing a HUBOT (HUman - roBOT).
The ALESIA application
We have implemented our ideas and techniques in a first system called ALESIA. In this system, agents are players. Their purpose is to learn to play a one-to-one stake game so as to constitute a collective expertise (a set of very effective agents that exchange strategies). Rules of the game are very simple:
|
At the beginning of the game, each player receives a capital of 50 points. Each move consists of a point combat : players decide simultaneously and secretly what number of points (at least one) they allocate to this move. The player that has chosen the highest number moves the marker (initially on the center) to the adverse citadel. In case of equal stakes, the marker doesn’t move. Played numbers are then deducted from the capital of the corresponding players. A player wins if he succeeds to displace the marker up to the adverse citadel. Otherwise, it’s a draw. |
Rome Alésia
Each behavioral rule has a simple linear structure that sets how much points to stake according to the current state of the game (remaining capital of each players, position of the marker, etc. ) and according to what an agent "expects" his opponent to play (the number of points that he is going to stake). Each rule has a selective value (fitness) that serves to distinguish efficient rules from inefficient rules. In particular, selective value are used to select which rule to apply when several rules are applicable in a given situation.
When an agent models another agent, he systematically records all the actions this agent performs in each situation and accordingly creates proper behavioral rules. Later on, such created rules may be generalized such as two rules likely to be applicable in similar circumstances and suggesting an identical action are regrouped in a single one. Gradually, an agent can thus record and model all his opponent’s behaviors.
Anticipation calls upon a more elaborate technique : the S.A.G.A.C.E. method (Meyer, 1996). In fact, when an agent creates a modelling rule, he allocates to this rule a given selective value, depending whether the rule has been efficient or not for the opponent. Thereafter, when the opponent plays again the same stake in similar circumstances, the selective value of the corresponding modelling rule is adjusted according to the opponent’s new gain. Such adjustments, which rely upon heuristics taking into account the utilization frequency of each rule and the record of how many times it has been successfully used, allows an agent to anticipate which rule another agent will use in which circumstances.
For example, imagine two players A and B playing one against the other and suppose that B attempts to model A and to anticipate his actions. Suppose also that A’s behavioral base is the following:
|
Rule N° |
Own’s capital |
Opponent’s capital |
Marker’s position |
stake |
Fitness |
|
1 |
50 |
1 à 50 |
O I I X I I O (center) |
10 |
11.2 |
|
2 |
50 |
1 à 50 |
O I I X I I O (center) |
12 |
9.3 |
|
3 |
[30,40] |
[10,50] |
O I I I X I O (one to right) |
8 |
7.3 |
|
... |
... |
... |
... |
... |
... |
Then, if A used rules 1,2 and 3 against B while his capital was respectively of 50, 50 and 38 points and while B’s capital was respectively of 50, 50 and 37 points, the three following rules will be created in the modelling basis of A by B:
|
Rule N° |
Own’s capital |
Opponent’s capital |
Marker’s position |
stake |
Fitness |
|
1 |
50 |
50 |
O I I X I I O (center) |
10 |
10.2 |
|
2 |
50 |
50 |
O I I X I I O (center) |
12 |
8.1 |
|
3 |
38 |
37 |
O I I I X I O (one to right) |
8 |
7.1 |
|
... |
... |
... |
... |
... |
... |
At rule creation, context information (like the capital of each player) is set to its correct value, which is known by the modelling agent. On the contrary, fitness values are estimated by means of a heuristic function and may differ from their correct values. B and A may have different criteria for performance evaluation and B can only guess at those of A.
If, later on, A uses again his rule N°3 while he has 30 points and while B has 39 points, then a possible generalization of the N°3 modelling rule of A by B may lead, for example, to change values 38 and 37 into intervals [30,38] and [37,39]. Future utilizations of rule N°3 by A will allow B to refine his generalization and therefore his model of A.
Finally, suppose that A plays again his rule N°1 and looses the game. The anticipation of A’s behavior by B will let him to decrease the fitness of his modelling rule N°1 (making it change, for example, from 10.2 to 7). A will make a similar change in his own basis (one supposes that A is correctly adaptive and that he "punishes" a rule that made him loose). Thus, the fitness of A’s behavioral rule will change, for example, from 11.2 to 9. Next time A will be in situation of using rule N°1 or rule N°2 (that have the same conditions of application), B will anticipate that A is going to use his rule N°2 whose fitness is now the highest. Thus B will anticipate that A is going to play 12 instead of 10.
Results
Results obtained with ALESIA are very encouraging. A human player entering the competition is often very effective at the beginning, but becomes rapidly inferior to hubots. Indeed, the latter model him very well and rapidly become capable of anticipating his actions and of countering him. However the short presence of a human in the system often allows the hubots to learn new strategies and to later evolve in new directions.
Moreover, thanks to the modelling and to the anticipation of human behavior, the system succeeds to discover rules that the human would probably have difficulties to formalize. As an example, an hubot discovered the following rule : " when the opponent has from 1 to 5 points, when I have at least 5 points more than him, and when, finally, the marker is one or two step(s) from the opponent’s citadel, then play 5 points ". Careful thinking is needed to convince oneself that, when this rule is applicable, it warrants victory.
The following results (Figure 1) have been obtained when combination of three different bootstrapping procedures and two evolving strategies have been used in a series of 400 games (distributed in 20 sets of 20 games) against a particular set of four players : one playing randomly (stake from 1 to 15 points at each move); another one using fixed rules (created by a human) with evolving fitnesses; a third one using 5000 randomly created rules with evolving fitnesses; and finally, a human player.
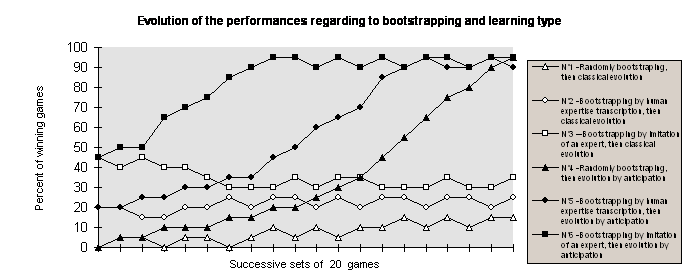 Figure 1
Figure 1
Player N°1 has been randomly bootstrapped (1000 randomly created rules) and evolved classically by modifying the fitness of these rules. Player N°2 has been bootstrapped with the help of rules designed by a human and evolved as player N°1. Player N°3 has been bootstrapped by playing against a human a hundred games during which he has modeled his behavior to learn good rule ; then he evolved as players N°1 and N°2. The three next players have been bootstrapped respectively as players N°1, N°2 and N°3 and evolved by modeling and anticipating actions of their different opponents.
Players that use modeling and anticipation (N°4, N°5 and N°6) improve quasi - constantly and eventually win almost 95% of games. However, the time necessary to get such results depends upon the bootstrapping strategy. Players using classical learning (N°1, N°2 and N°3) ultimately get a quasi - constant and weak gain. Player N°3 (who is a perfect copy of player N°6 after bootstrapping) has good results at the beginning but his score declines during the 150 first games. This is due to the fact that some of his opponents evolve and are likely to adapt to good rules that he has learnt during his bootstrapping stage and to the fact that he has no means to discover new rules.
Within such an application, it can be shown that a group of players, trained to compete against each other, eventually generates different modelling bases and that such an heterogeneity enhances the chances of beating any newcomer and of resisting to its invasion.
Particular interest for a DAI system
This method of imitation and anticipation has a lot of advantages for bootstrapping and then learning in a DAI system. It allows the agents to evolve freely based on previous observations of efficient behaviors. The freedom of interpretation is given to the agents so as they could use their own functioning diagram for learning.
By so doing, in ALESIA, some players evolve in different ways depending on their experiments and on their different interpretations. This possibility prevents that all the agents might become too similar, precisely, diversity is very useful - even necessary - in DAI system.
In others respects, using this method, it becomes unnecessary to create communication procedures - which is not always easy : the agents may transmit knowledge just by acting and modelling instead of communicating.
Conclusion
Such an approach based on the observation of animal behavior proves to be very efficient in this application despite the possible errors made by the generalization and anticipation mechanisms that we have implemented. Whether such errors turn out to have more dramatic effects in other, more challenging, applications remains to be sought. Be as it may, the methodology that has been explored herein already has numerous possible application in areas where human expertise is needed to initialize and maintain a system. This is for instance the case with expert systems, software agents, robotics, etc.
References:
Galef, B.G. 1992. The question of animal culture. Human Nature, 3, 157-178. Goldberg, D.E. 1989. Genetic Algorithms in Search, Optimization, and Machine learning. Addison-Wesley. Heyes, C.M. 1994. Animal learning and cognition,, chap 10. Academic Press. Heyes, C.M. 1993. Imitation, Culture and Cognition. Animal Behavior, 46, 999-1010. Hinde, R.A. and Fischer, J. 1951. Further observations on the opening of milk bottles by birds. Brit. Birds. 44,396-399. Holland, J.H. 1975. Adaptation in Natural and Artificial Systems. University of Michigan Press. Holland, J.H ; Holyoak, K.J. Thagard, P.R. and Nisbet, R.E. 1986. Induction : Processes of Inference, Learning, and Discovery. MIT Press, Cambridge Kawanura, S.1963. The process of sub-culture propagation among Japanese macaques, In Southwick, C.H.(Ed.) Primate social behavior. Van Nostrand Meyer, C. 1996 S.A.G.A.C.E. : Solution Algorithmique Génétique pour l’Anticipation de Comportements Evolutifs. Laforia, Rapport interne (Internal report). Murie, A. 1944. The wolfes of Mount McKinley. Faune of the national parks of the USA. Fauna Series,5. Schimdt-Koenig,K. 1979 Avian orientation and navigation, Academic Press.